これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用できます:
Chain of Densityを使用した要約
重要な詳細を保持しながら複雑な技術文書を要約することは難しい課題です。Chain of Density(CoD)要約技術は、要約を繰り返し改良してより簡潔で情報密度の高いものにすることで解決策を提供します。このガイドでは、Weaveを使用してアプリケーションの追跡と評価を行いながらCoDを実装する方法を示します。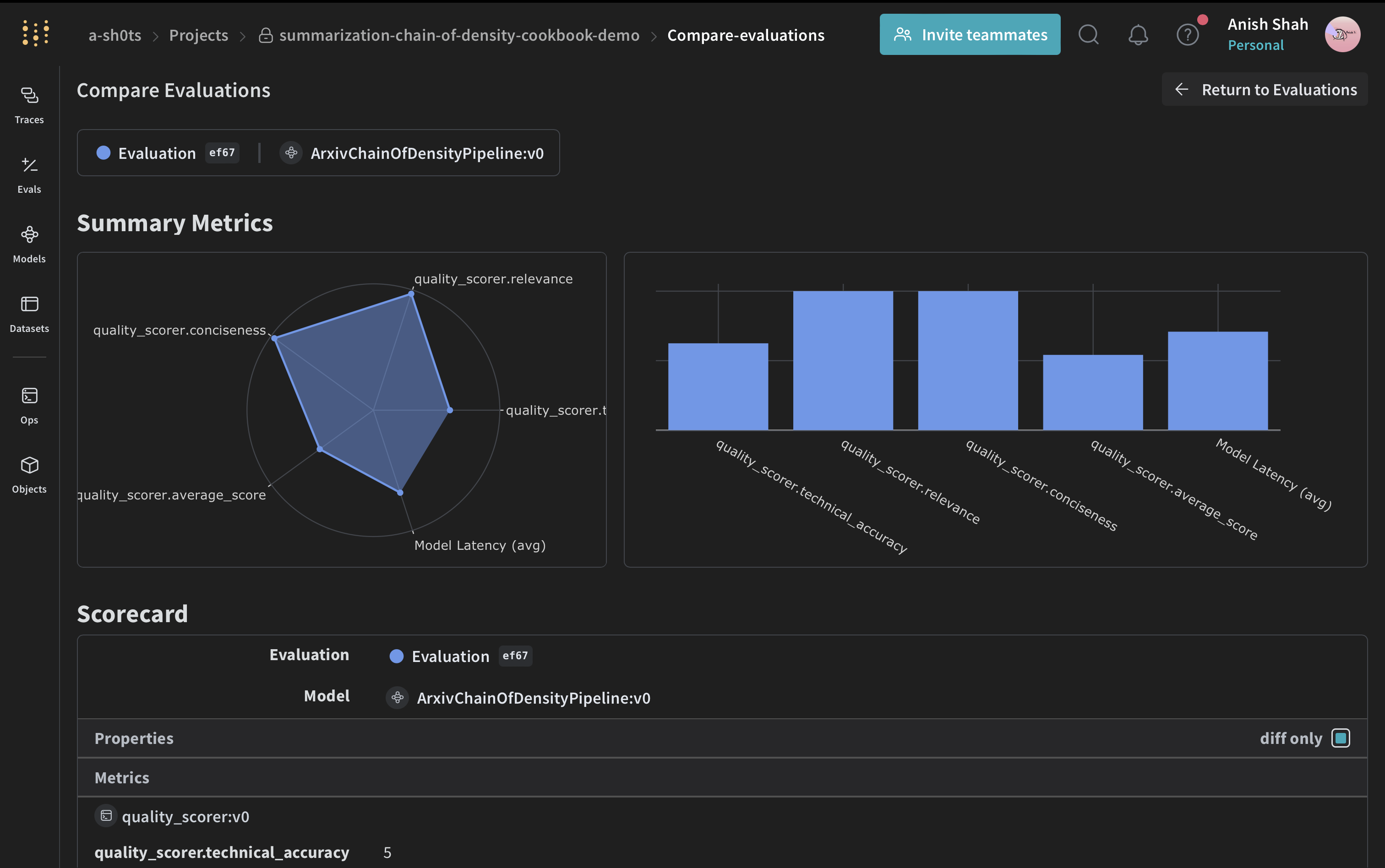
Chain of Density要約とは何か?
- 初期要約から始める
- 要約を繰り返し改良し、重要な情報を保持しながらより簡潔にする
- 各反復でエンティティと技術的詳細の密度を高める
なぜWeaveを使用するのか?
このチュートリアルでは、ArXiv論文のChain of Density要約パイプラインを実装し評価するためにWeaveを使用します。以下の方法を学びます:- LLMパイプラインを追跡する: Weaveを使用して、要約プロセスの入力、出力、および中間ステップを自動的に記録します。
- LLM出力を評価する: Weaveの組み込みツールを使用して、要約の厳密な同条件での評価を作成します。
- 構成可能な操作を構築する: Weave操作を組み合わせて、要約パイプラインの異なる部分で再利用します。
- シームレスに統合: 最小限のオーバーヘッドで既存のPythonコードにWeaveを追加します。
環境をセットアップする
まず、環境をセットアップし、必要なライブラリをインポートしましょう:Anthropic APIキーを取得するには:
- アカウントに登録する https://www.anthropic.com
- アカウント設定のAPIセクションに移動
- 新しいAPIキーを生成
- APIキーを.envファイルに安全に保存
weave.init(<project name>) 呼び出しは、要約タスク用の新しいWeaveプロジェクトをセットアップします。
ArxivPaperモデルを定義する
シンプルなArxivPaper クラスを作成してデータを表現します:
PDFコンテンツを読み込む
論文の全文を扱うために、PDFからテキストを読み込んで抽出する関数を追加します:Chain of Density要約を実装する
では、Weave操作を使用してコアとなるCoD要約ロジックを実装しましょう: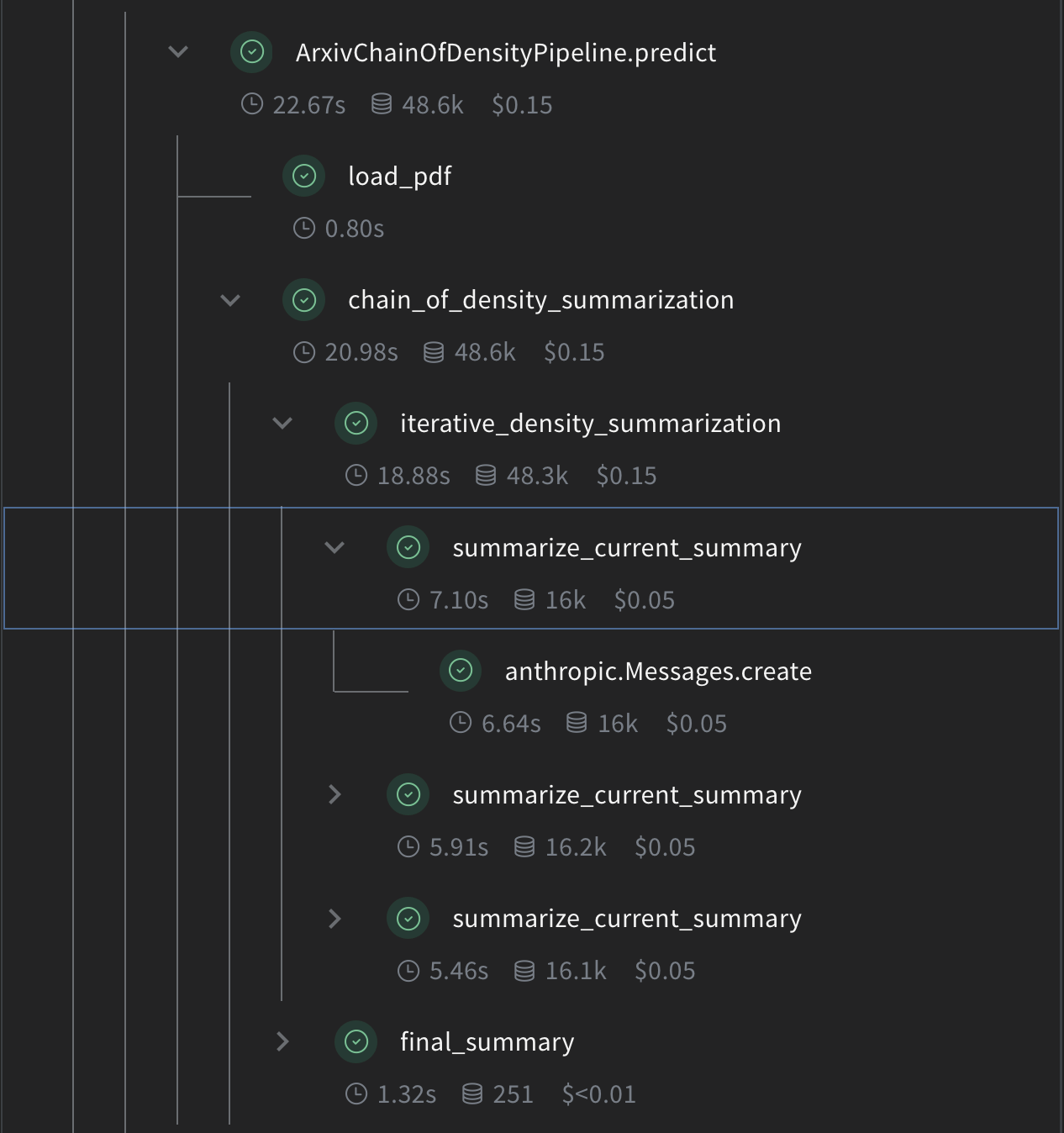
summarize_current_summary: 現在の状態に基づいて単一の要約イテレーションを生成します。iterative_density_summarization:summarize_current_summaryを複数回呼び出すことでCoD技術を適用します。chain_of_density_summarization: 要約プロセス全体を調整し、結果を返します。
@weave.op() デコレータを使用することで、Weaveがこれらの関数の入力、出力、実行を追跡することを保証します。
Weave Modelを作成する
次に、要約パイプラインをWeave Modelでラップしましょう: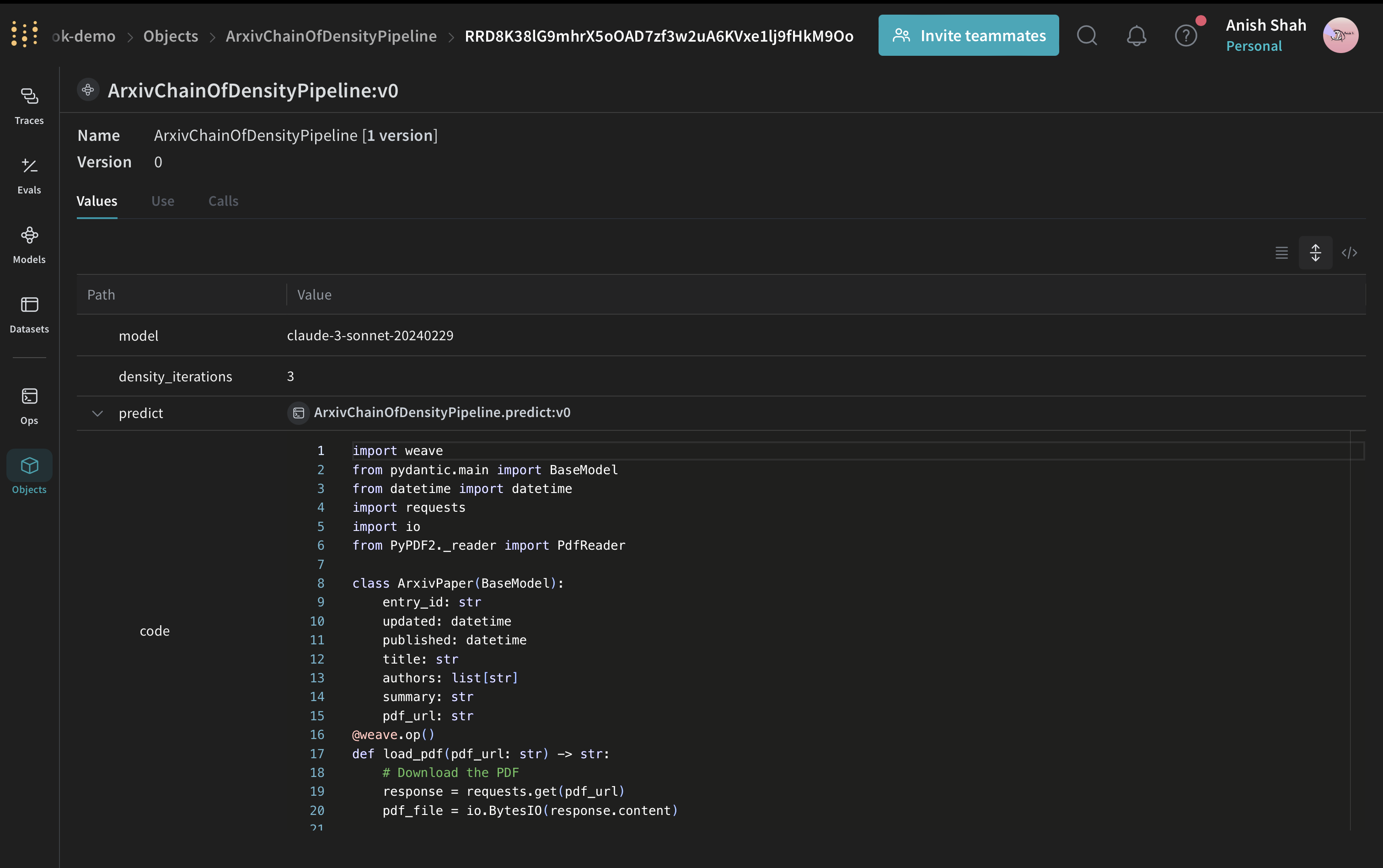
ArxivChainOfDensityPipeline クラスは要約ロジックをWeave Modelとしてカプセル化し、いくつかの重要な利点を提供します:
- 自動実験追跡:Weaveはモデルの各実行の入力、出力、パラメータをキャプチャします。
- Versioning: Changes to the model’s attributes or code are automatically versioned, creating a clear history of how your summarization pipeline evolves over time.
- Reproducibility: The versioning and tracking make it easy to reproduce any previous result or configuration of your summarization pipeline.
- ハイパーパラメータ管理:モデル属性(
modelやdensity_iterations)は明確に定義され、異なる実行間で追跡され、実験を容易にします。 - Weaveエコシステムとの統合:
weave.Modelを使用することで、評価や提供機能などの他のWeaveツールとシームレスに統合できます。
評価指標を実装する
要約の品質を評価するために、シンプルな評価指標を実装します:Weave Datasetを作成し評価を実行する
パイプラインを評価するために、Weave Datasetを作成し評価を実行します: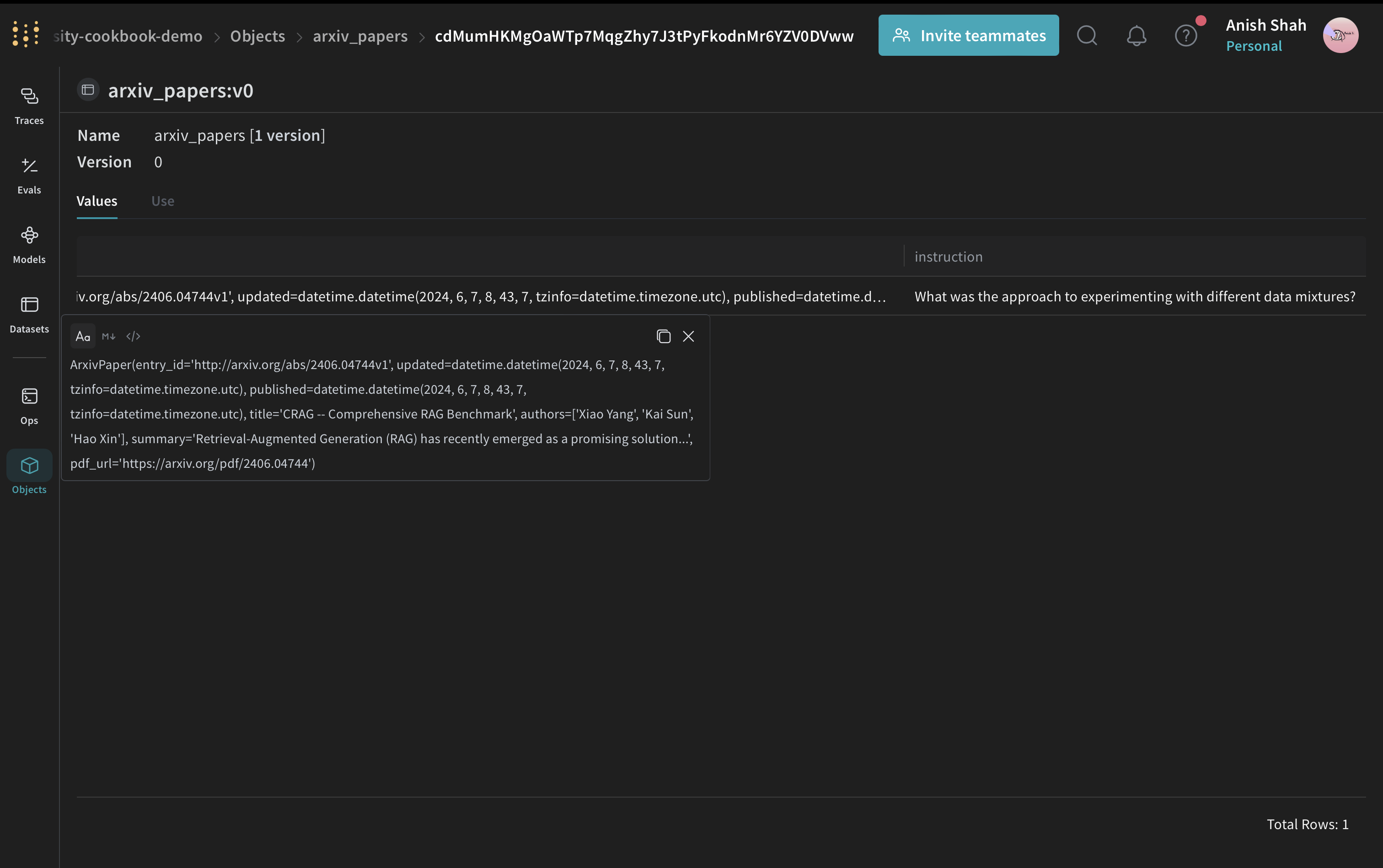
結論
この例では、Weaveを使用してArXiv論文のChain of Density要約パイプラインを実装する方法を示しました。以下の方法を示しました:- 要約プロセスの各ステップにWeave操作を作成する
- パイプラインをWeave Modelでラップして、簡単な追跡と評価を可能にする
- Weave操作を使用してカスタム評価指標を実装する
- データセットを作成し、パイプラインの評価を実行する