これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用できます:
DSPyとWeaveを使用したLLMワークフローの最適化
この BIG-bench(Beyond the Imitation Game Benchmark) は、大規模言語モデルを検証し、その将来の能力を推定することを目的とした、200以上のタスクで構成される共同ベンチマークです。BIG-Bench Hard(BBH) は、現世代の言語モデルでは解決が非常に困難な、BIG-Benchの最も挑戦的な23のタスクのスイートです。 このチュートリアルでは、BIG-bench Hardベンチマークの causal judgement task で実装されたLLMワークフローのパフォーマンスを向上させ、プロンプト戦略を評価する方法を示します。DSPy LLMワークフローの実装とプロンプト戦略の最適化のために使用します。また Weave を使用してLLMワークフローを追跡し、プロンプト戦略を評価します。依存関係のインストール
このチュートリアルでは以下のライブラリが必要です:- DSPy LLMワークフローの構築と最適化のため。
- Weave LLMワークフローの追跡とプロンプト戦略の評価のため。
- datasets HuggingFace HubからBig-Bench Hardデータセットにアクセスするため。
Weaveを使用した追跡の有効化
WeaveはDSPyと現在統合されており、コードの先頭にweave.init を含めることで、Weave UIで探索できるDSPy関数を自動的にトレースできます。詳細については、Weave integration docs for DSPy をご覧ください。
weave.Object から継承したメタデータクラスを使用してメタデータを管理します。
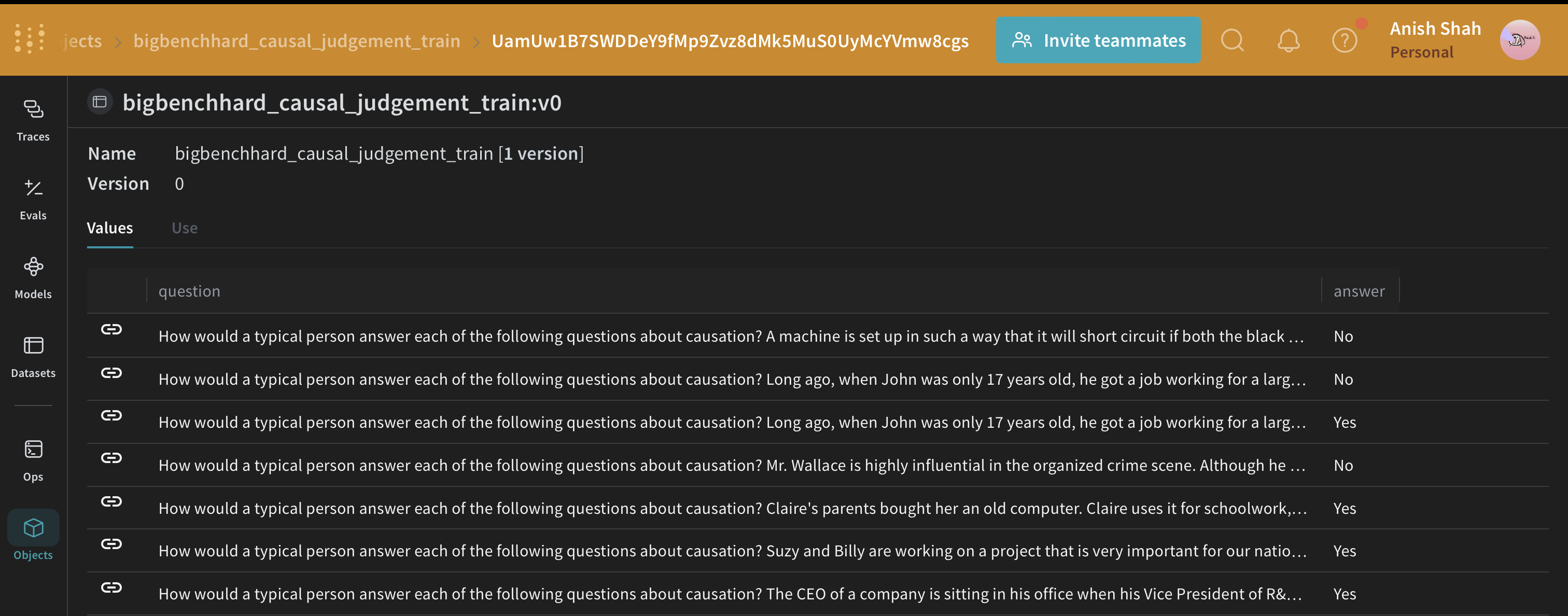
BIG-Bench Hardデータセットの読み込み
このデータセットをHuggingFace Hubから読み込み、トレーニングセットと検証セットに分割し、publish でWeaveに公開します。これによりデータセットのバージョン管理が可能になり、weave.Evaluation を使用してプロンプト戦略を評価することもできます。
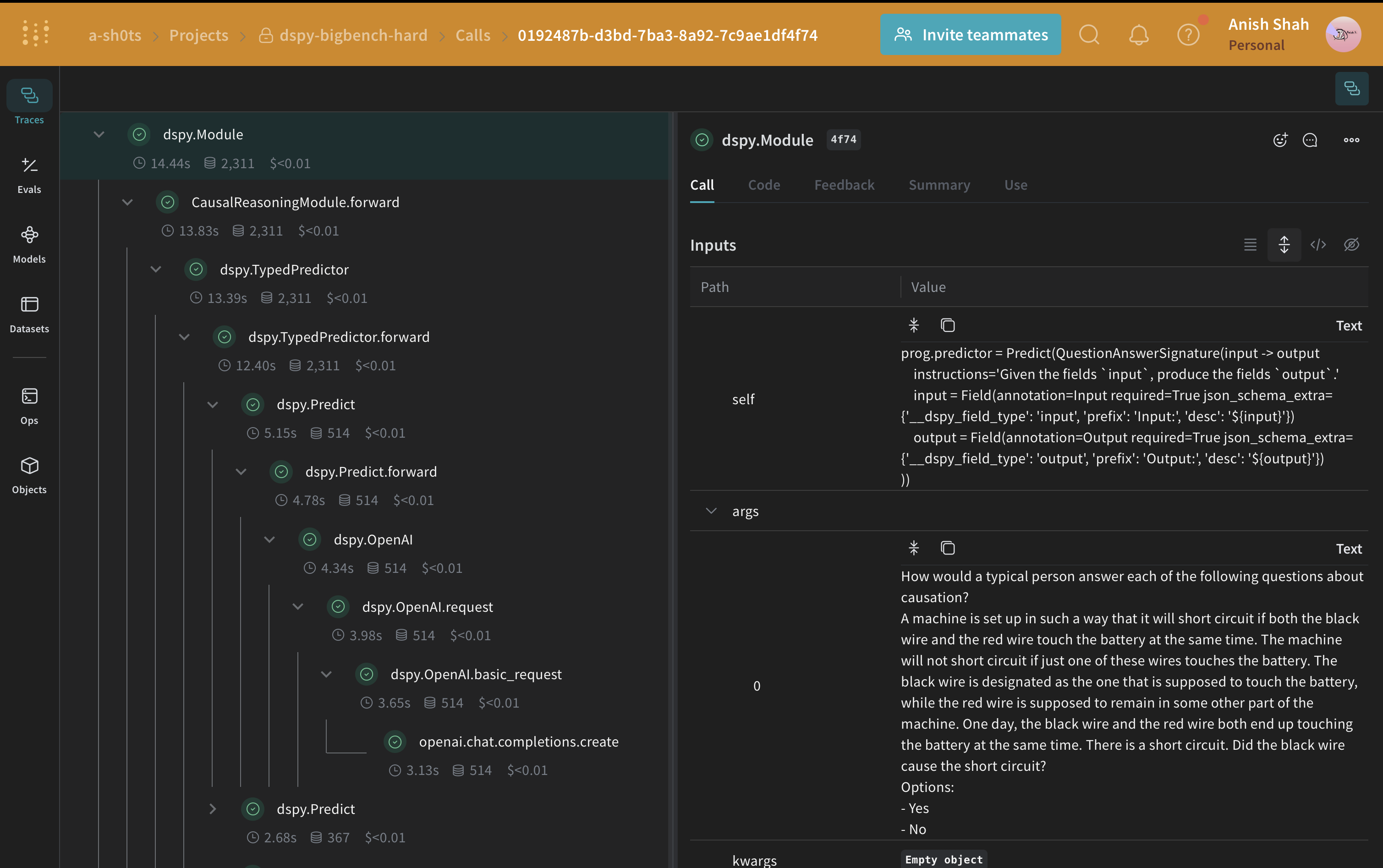
DSPyプログラム
DSPy は、自由形式の文字列を操作することから離れ、プログラミング(モジュラーな演算子を組み合わせてテキスト変換グラフを構築する)に近づけるフレームワークであり、コンパイラがプログラムから最適化されたLM呼び出し戦略とプロンプトを自動的に生成します。 私たちはdspy.OpenAI 抽象化を使用して GPT3.5 TurboへのLLM呼び出しを行います。
因果推論シグネチャの作成
signature は DSPy module の入出力動作の宣言的な仕様であり、これはタスク適応型コンポーネント(ニューラルネットワークの層に似ている)で、特定のテキスト変換を抽象化します。CausalReasoningModule)をテストしてみましょう。
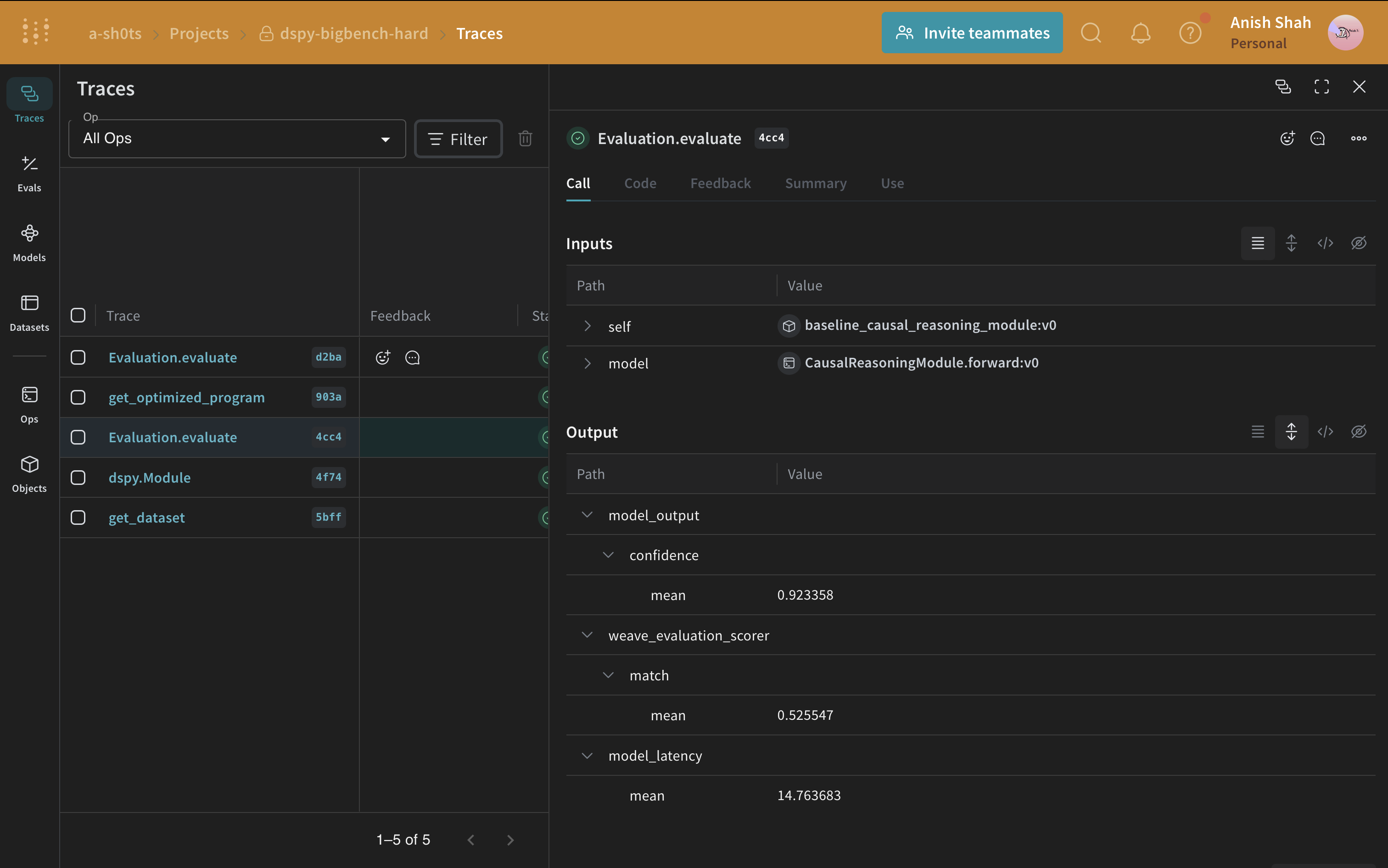
DSPyプログラムの評価
ベースラインのプロンプト戦略ができたので、予測された回答と正解を照合する単純なメトリックを使用して、weave.Evaluation で検証セットで評価してみましょう。Weaveは各例を取り、アプリケーションを通過させ、複数のカスタムスコアリング関数で出力をスコアリングします。これにより、アプリケーションのパフォーマンスの概要と、個々の出力とスコアを詳しく調査するためのリッチなUIが得られます。
まず、ベースラインモジュールの出力からの回答が正解と同じかどうかを判断する単純なweave評価スコアリング関数を作成する必要があります。スコアリング関数には model_output キーワード引数が必要ですが、他の引数はユーザー定義であり、データセットの例から取得されます。引数名に基づいた辞書キーを使用して、必要なキーのみを取得します。
Pythonスクリプトから実行している場合は、以下のコードを使用して評価を実行できます:
DSPyプログラムの最適化
ベースラインのDSPyプログラムができたので、DSPy teleprompter を使用して因果推論のパフォーマンスを向上させてみましょう。これは指定されたメトリックを最大化するためにDSPyプログラムのパラメータを調整できます。このチュートリアルでは、BootstrapFewShot テレプロンプターを使用します。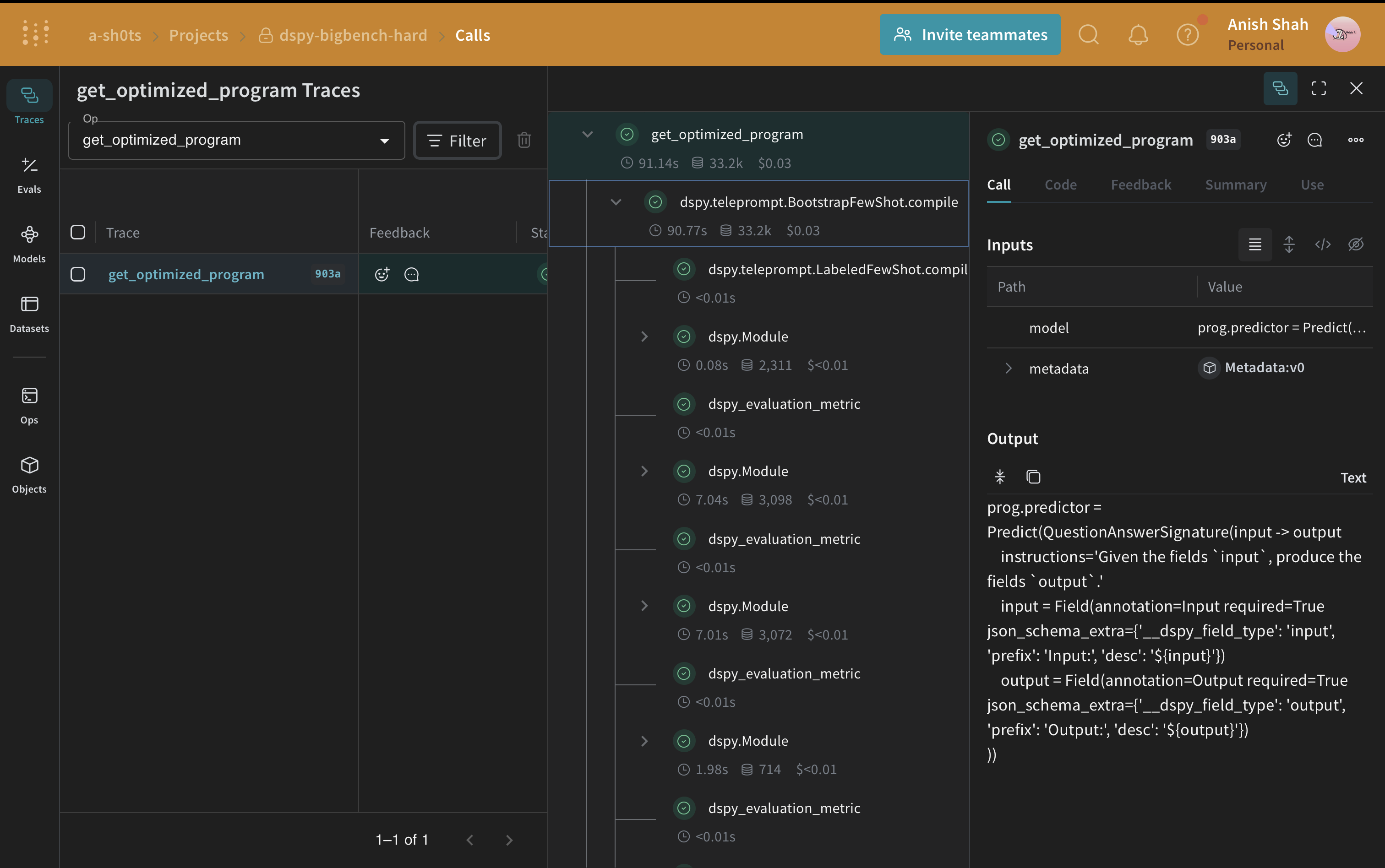 最適化されたプログラム(最適化されたプロンプト戦略)ができたので、もう一度検証セットで評価し、ベースラインのDSPyプログラムと比較してみましょう。
最適化されたプログラム(最適化されたプロンプト戦略)ができたので、もう一度検証セットで評価し、ベースラインのDSPyプログラムと比較してみましょう。
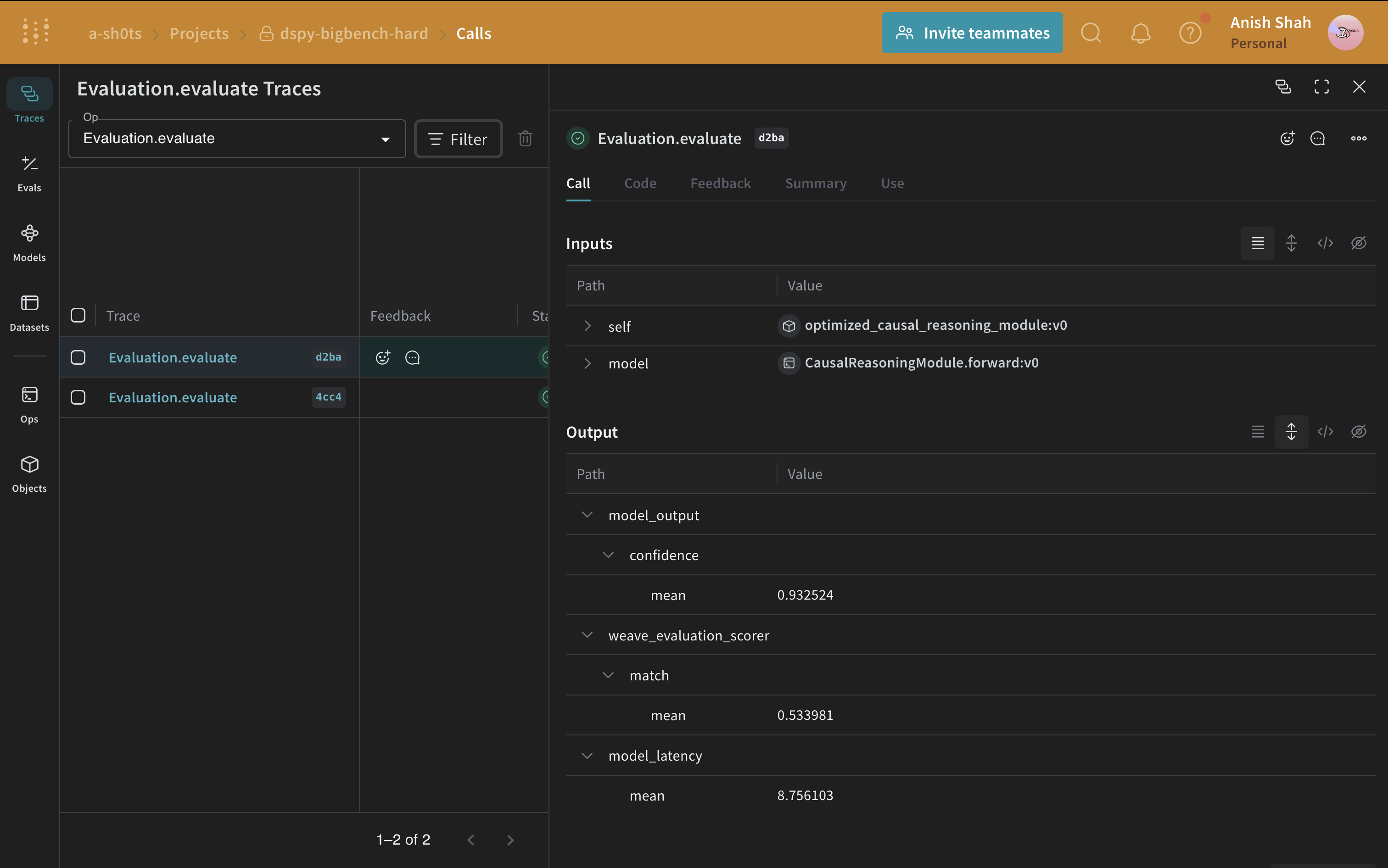 ベースラインプログラムと最適化されたプログラムの評価を比較すると、最適化されたプログラムは因果推論の質問に対してはるかに高い精度で回答していることがわかります。
ベースラインプログラムと最適化されたプログラムの評価を比較すると、最適化されたプログラムは因果推論の質問に対してはるかに高い精度で回答していることがわかります。