이것은 대화형 노트북입니다. 로컬에서 실행하거나 아래 링크를 사용할 수 있습니다:
Chain of Density를 사용한 요약
중요한 세부 정보를 보존하면서 복잡한 기술 문서를 요약하는 것은 어려운 작업입니다. Chain of Density(CoD) 요약 기술은 요약을 반복적으로 개선하여 더 간결하고 정보가 풍부하게 만드는 솔루션을 제공합니다. 이 가이드는 Weave를 사용하여 애플리케이션을 추적하고 평가하는 CoD를 구현하는 방법을 보여줍니다.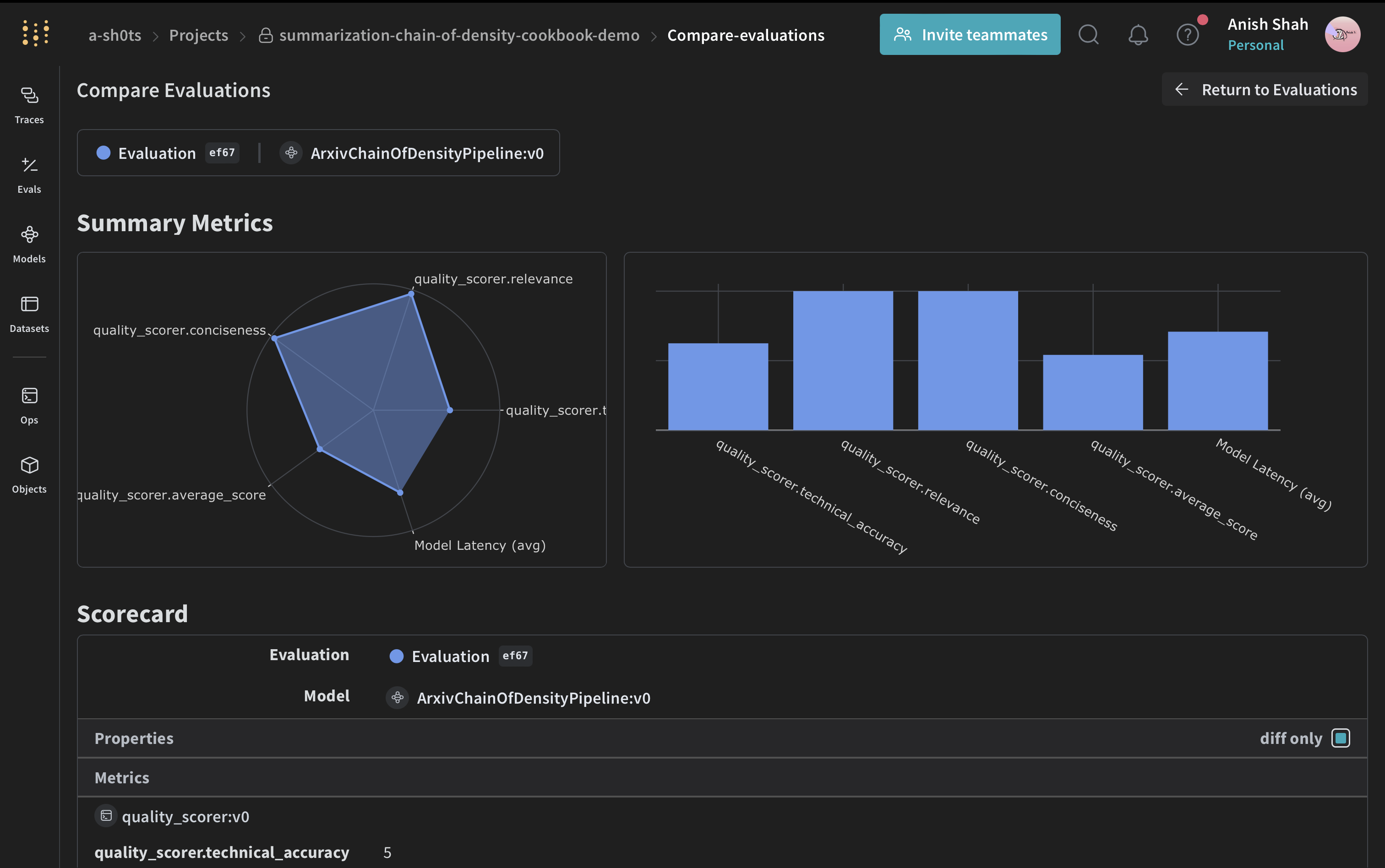
Chain of Density 요약이란 무엇인가요?
- 초기 요약으로 시작
- 핵심 정보를 보존하면서 요약을 더 간결하게 만들어 반복적으로 개선
- 각 반복마다 엔티티와 기술적 세부 사항의 밀도 증가
Weave를 사용하는 이유는 무엇인가요?
이 튜토리얼에서는 Weave를 사용하여 ArXiv 논문을 위한 Chain of Density 요약 파이프라인을 구현하고 평가할 것입니다. 다음을 배우게 됩니다:- LLM 파이프라인 추적: Weave를 사용하여 요약 프로세스의 입력, 출력 및 중간 단계를 자동으로 기록하세요.
- LLM 출력 평가하기: Weave의 내장 도구를 사용하여 엄격하고 동등한 조건에서의 요약 평가를 생성하세요.
- 구성 가능한 작업 구축하기: Weave 작업을 요약 파이프라인의 다양한 부분에서 결합하고 재사용하세요.
- 원활한 통합: 최소한의 오버헤드로 기존 Python 코드에 Weave를 추가하세요.
환경 설정하기
먼저, 환경을 설정하고 필요한 라이브러리를 가져오겠습니다:Anthropic API 키를 얻으려면:
- 다음에서 계정에 가입하세요 https://www.anthropic.com
- 계정 설정에서 API 섹션으로 이동하세요
- 새 API 키를 생성하세요
- API 키를 .env 파일에 안전하게 저장하세요
weave.init(<project name>) 호출은 요약 작업을 위한 새로운 Weave 프로젝트를 설정합니다.
ArxivPaper 모델 정의하기
간단한ArxivPaper 클래스를 만들어 데이터를 표현하겠습니다:
PDF 내용 로드하기
전체 논문 내용으로 작업하기 위해 PDF에서 텍스트를 로드하고 추출하는 함수를 추가하겠습니다:Chain of Density 요약 구현하기
이제 Weave 작업을 사용하여 핵심 CoD 요약 로직을 구현해 보겠습니다: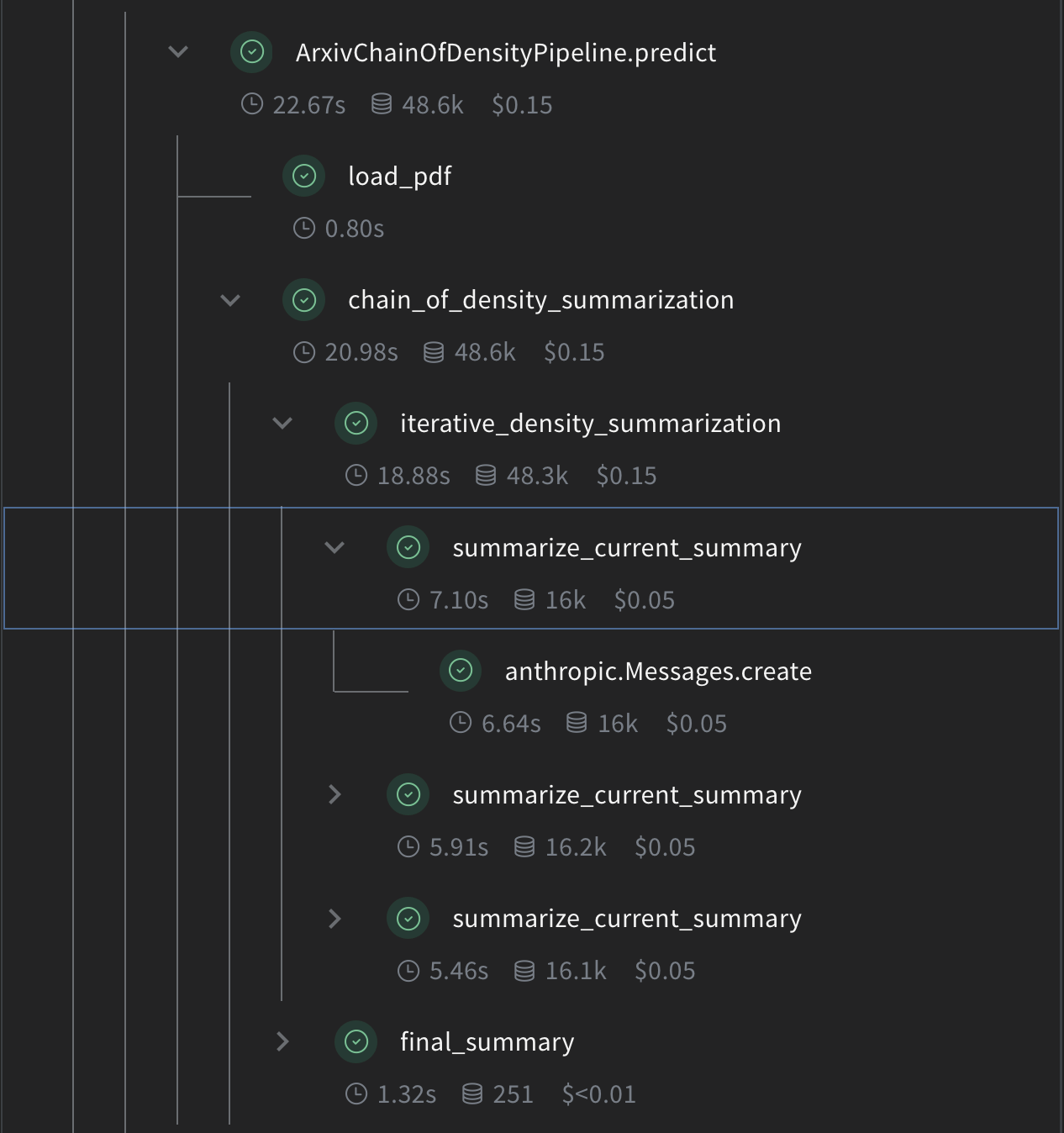
summarize_current_summary: 현재 상태를 기반으로 단일 요약 반복을 생성합니다.iterative_density_summarization: CoD 기법을 적용하기 위해summarize_current_summary를 여러 번 호출합니다.chain_of_density_summarization: 전체 요약 프로세스를 조율하고 결과를 반환합니다.
@weave.op() 데코레이터를 사용함으로써 Weave가 이러한 함수의 입력, 출력 및 실행을 추적하도록 보장합니다.
Weave 모델 만들기
이제 요약 파이프라인을 Weave 모델로 래핑해 보겠습니다: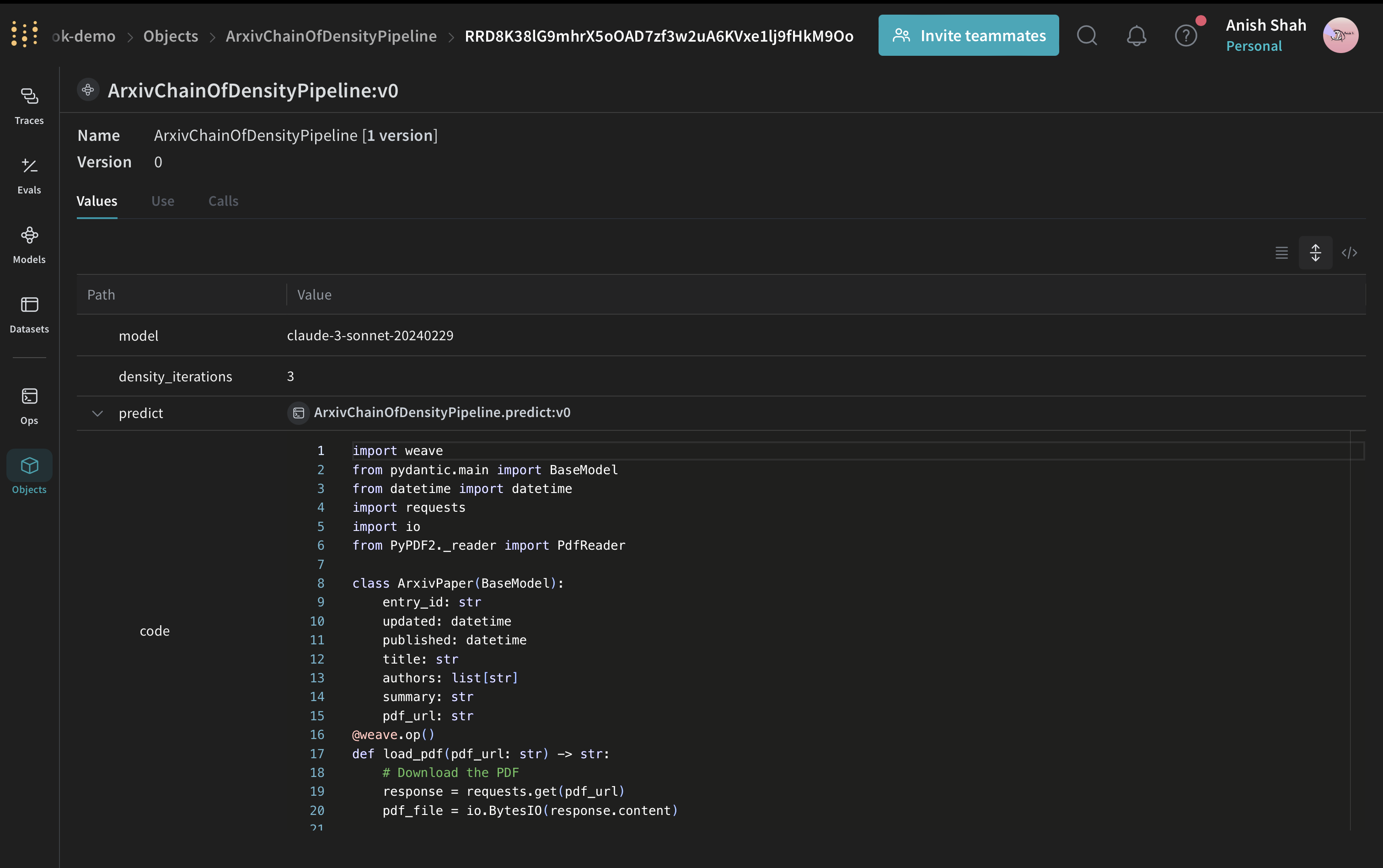
ArxivChainOfDensityPipeline 클래스는 요약 로직을 Weave 모델로 캡슐화하여 다음과 같은 주요 이점을 제공합니다:
- 자동 실험 추적: Weave는 모델의 각 실행에 대한 입력, 출력 및 매개변수를 캡처합니다.
- Versioning: Changes to the model’s attributes or code are automatically versioned, creating a clear history of how your summarization pipeline evolves over time.
- Reproducibility: The versioning and tracking make it easy to reproduce any previous result or configuration of your summarization pipeline.
- 하이퍼파라미터 관리: 모델 속성(예:
model와density_iterations)이 명확하게 정의되고 다양한 실행에서 추적되어 실험을 용이하게 합니다. - Weave 생태계와의 통합:
weave.Model를 사용하면 평가 및 서빙 기능과 같은 다른 Weave 도구와 원활하게 통합할 수 있습니다.
평가 지표 구현하기
요약의 품질을 평가하기 위해 간단한 평가 지표를 구현하겠습니다:Weave 데이터셋 생성 및 평가 실행하기
파이프라인을 평가하기 위해 Weave 데이터셋을 만들고 평가를 실행하겠습니다: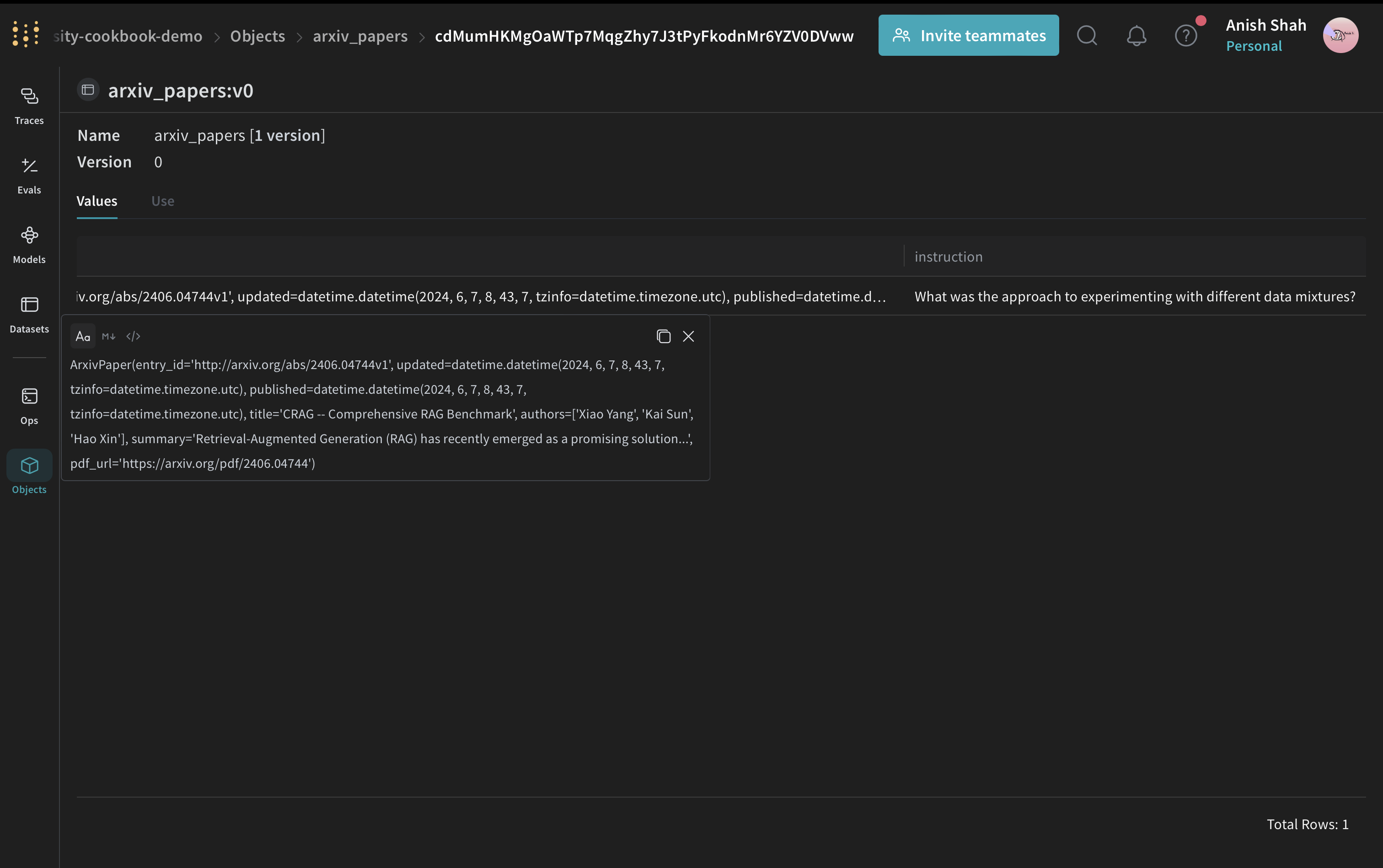
결론
이 예제에서는 Weave를 사용하여 ArXiv 논문을 위한 Chain of Density 요약 파이프라인을 구현하는 방법을 보여주었습니다. 다음과 같은 방법을 보여주었습니다:- 요약 프로세스의 각 단계에 대한 Weave 작업 생성하기
- 쉬운 추적 및 평가를 위해 파이프라인을 Weave 모델로 래핑하기
- Weave 작업을 사용하여 사용자 정의 평가 지표 구현하기
- 데이터셋을 생성하고 파이프라인 평가 실행하기