이것은 인터랙티브 노트북입니다. 로컬에서 실행하거나 아래 링크를 사용할 수 있습니다:
DSPy와 Weave를 사용한 LLM 워크플로우 최적화
The BIG-bench (Beyond the Imitation Game Benchmark)는 대규모 언어 모델을 테스트하고 미래 기능을 추론하기 위한 200개 이상의 작업으로 구성된 협업 벤치마크입니다. BIG-Bench Hard (BBH)는 현재 세대의 언어 모델로 해결하기 매우 어려울 수 있는 23개의 가장 도전적인 BIG-Bench 작업 모음입니다. 이 튜토리얼은 BIG-bench Hard 벤치마크의 causal judgement task에서 구현된 LLM 워크플로우의 성능을 향상시키고 프롬프팅 전략을 평가하는 방법을 보여줍니다. 우리는 DSPy LLM 워크플로우를 구현하고 프롬프트 전략을 최적화하기 위해 사용할 것입니다. 또한 Weave를 사용하여 LLM 워크플로우를 추적하고 프롬프트 전략을 평가할 것입니다.의존성 설치하기
이 튜토리얼에는 다음 라이브러리가 필요합니다:- DSPy - LLM 워크플로우를 구축하고 최적화하기 위해 사용합니다.
- Weave - LLM 워크플로우를 추적하고 프롬프트 전략을 평가하기 위해 사용합니다.
- datasets - HuggingFace Hub에서 Big-Bench Hard 데이터셋에 접근하기 위해 사용합니다.
Weave를 사용한 추적 활성화
Weave는 현재 DSPy와 통합되어 있으며, 코드 시작 부분에weave.init를 포함하면 DSPy 함수를 자동으로 추적할 수 있으며 이는 Weave UI에서 탐색할 수 있습니다. 자세한 내용은 Weave integration docs for DSPy를 확인하세요.
weave.Object에서 상속받은 메타데이터 클래스를 사용하여 메타데이터를 관리합니다.
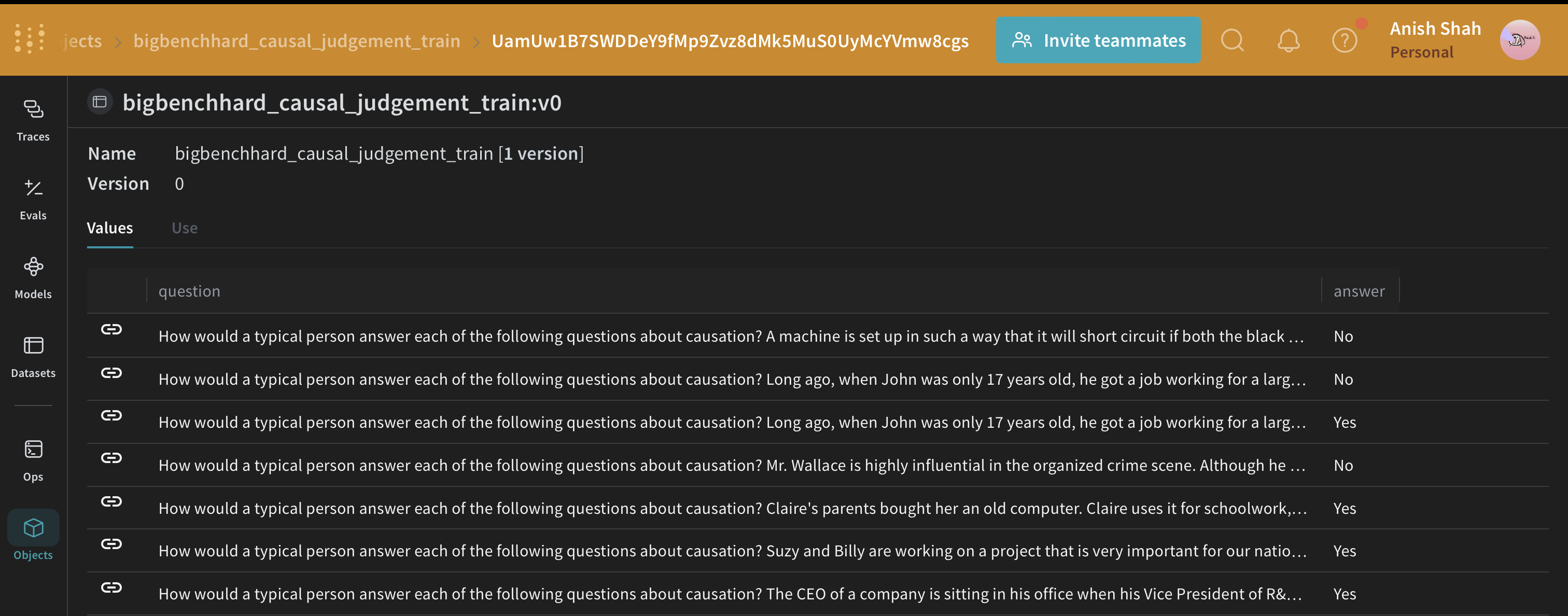
BIG-Bench Hard 데이터셋 로드하기
HuggingFace Hub에서 이 데이터셋을 로드하고, 훈련 및 검증 세트로 분할한 다음, publish를 통해 Weave에 게시할 것입니다. 이를 통해 데이터셋의 버전을 관리하고weave.Evaluation를 사용하여 프롬프트 전략을 평가할 수 있습니다.
DSPy 프로그램
DSPy는 자유 형식의 문자열을 조작하는 것에서 벗어나 프로그래밍(모듈식 연산자를 구성하여 텍스트 변환 그래프 구축)에 가까운 새로운 LM 파이프라인 구축을 추진하는 프레임워크로, 컴파일러가 프로그램에서 최적화된 LM 호출 전략과 프롬프트를 자동으로 생성합니다. 우리는dspy.OpenAI 추상화를 사용하여 GPT3.5 Turbo에 LLM 호출을 할 것입니다.
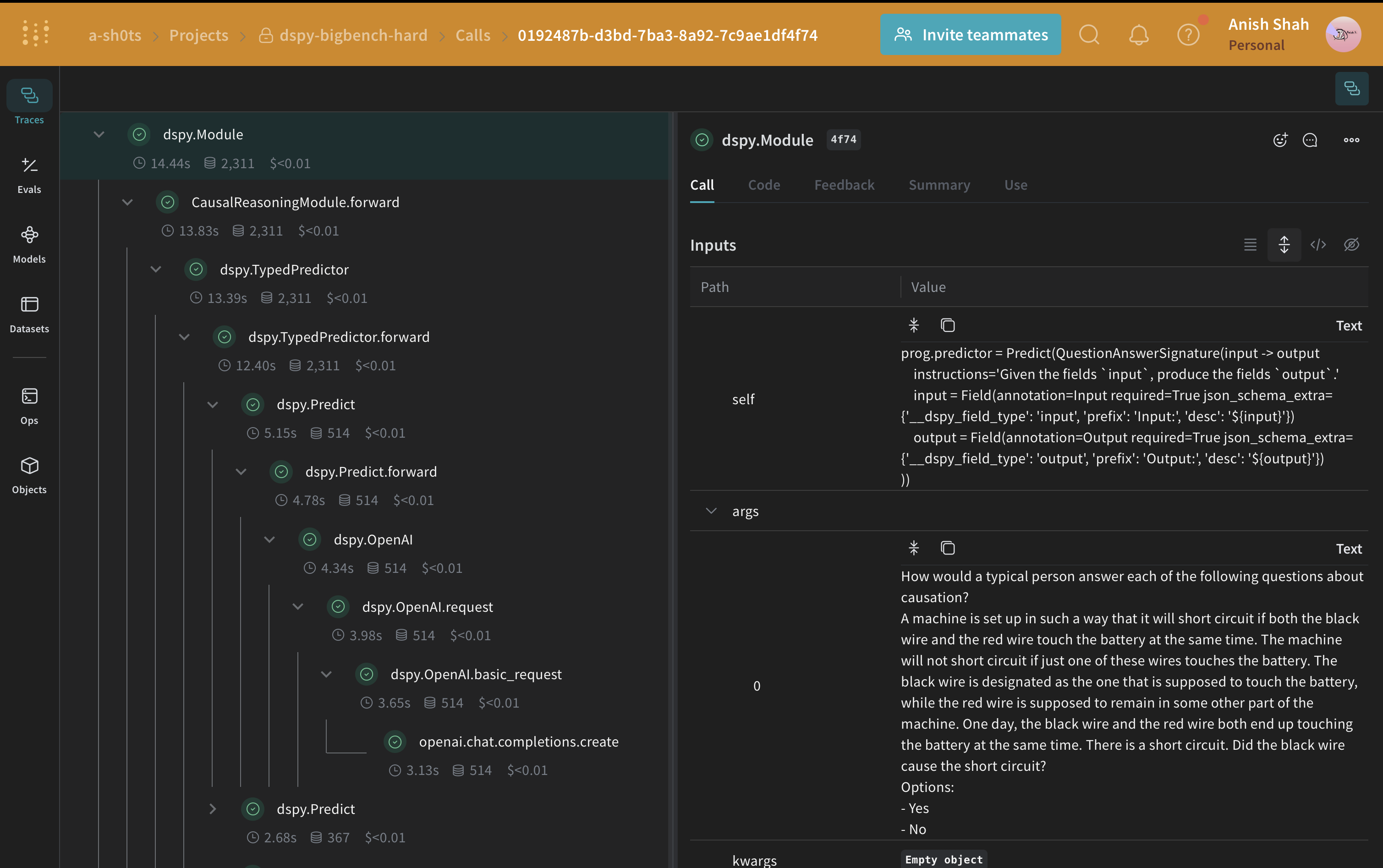
인과 추론 시그니처 작성하기
signature는 DSPy module의 입력/출력 동작에 대한 선언적 명세로, 이는 특정 텍스트 변환을 추상화하는 작업 적응형 컴포넌트(신경망 레이어와 유사)입니다.CausalReasoningModule를 테스트해 봅시다.
DSPy 프로그램 평가하기
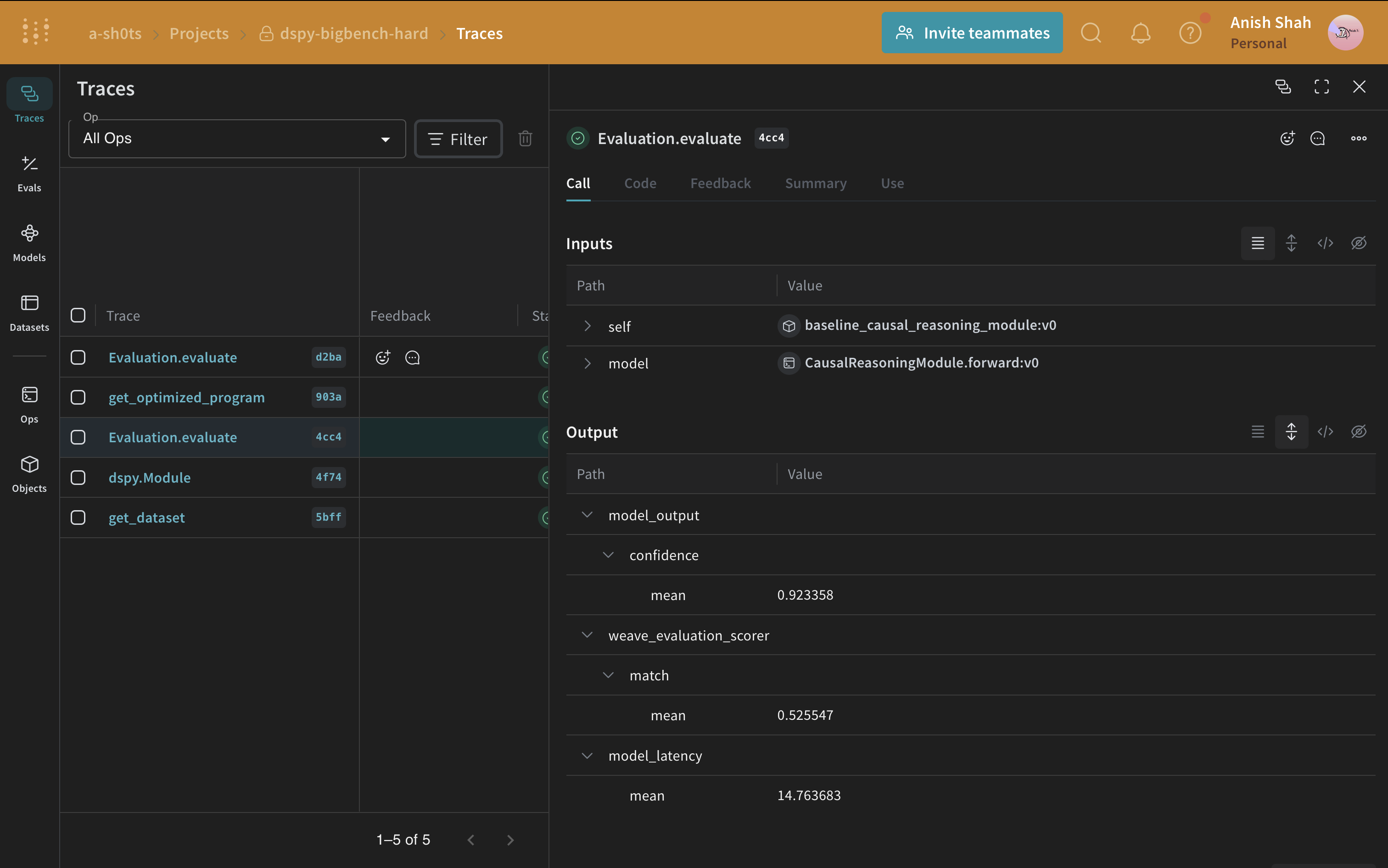
이제 기본 프롬프트 전략이 있으니,weave.Evaluation를 사용하여 예측된 답변과 실제 정답을 비교하는 간단한 메트릭으로 검증 세트에서 평가해 봅시다. Weave는 각 예제를 가져와 애플리케이션을 통과시키고 여러 사용자 정의 점수 함수로 출력을 평가합니다. 이를 통해 애플리케이션의 성능을 볼 수 있고, 개별 출력과 점수를 자세히 살펴볼 수 있는 풍부한 UI를 갖게 됩니다.
먼저, 기준 모듈의 출력에서 나온 답변이 실제 정답과 동일한지 여부를 알려주는 간단한 weave 평가 점수 함수를 만들어야 합니다. 점수 함수는 model_output 키워드 인수가 필요하지만, 다른 인수는 사용자 정의이며 데이터셋 예제에서 가져옵니다. 인수 이름을 기반으로 한 사전 키를 사용하여 필요한 키만 가져올 것입니다.
Python 스크립트에서 실행하는 경우, 다음 코드를 사용하여 평가를 실행할 수 있습니다:
DSPy 프로그램 최적화하기
이제 기본 DSPy 프로그램이 있으니, DSPy teleprompter를 사용하여 인과 추론에 대한 성능을 향상시켜 보겠습니다. 이는 지정된 메트릭을 최대화하기 위해 DSPy 프로그램의 매개변수를 조정할 수 있습니다. 이 튜토리얼에서는 BootstrapFewShot 텔레프롬프터를 사용합니다.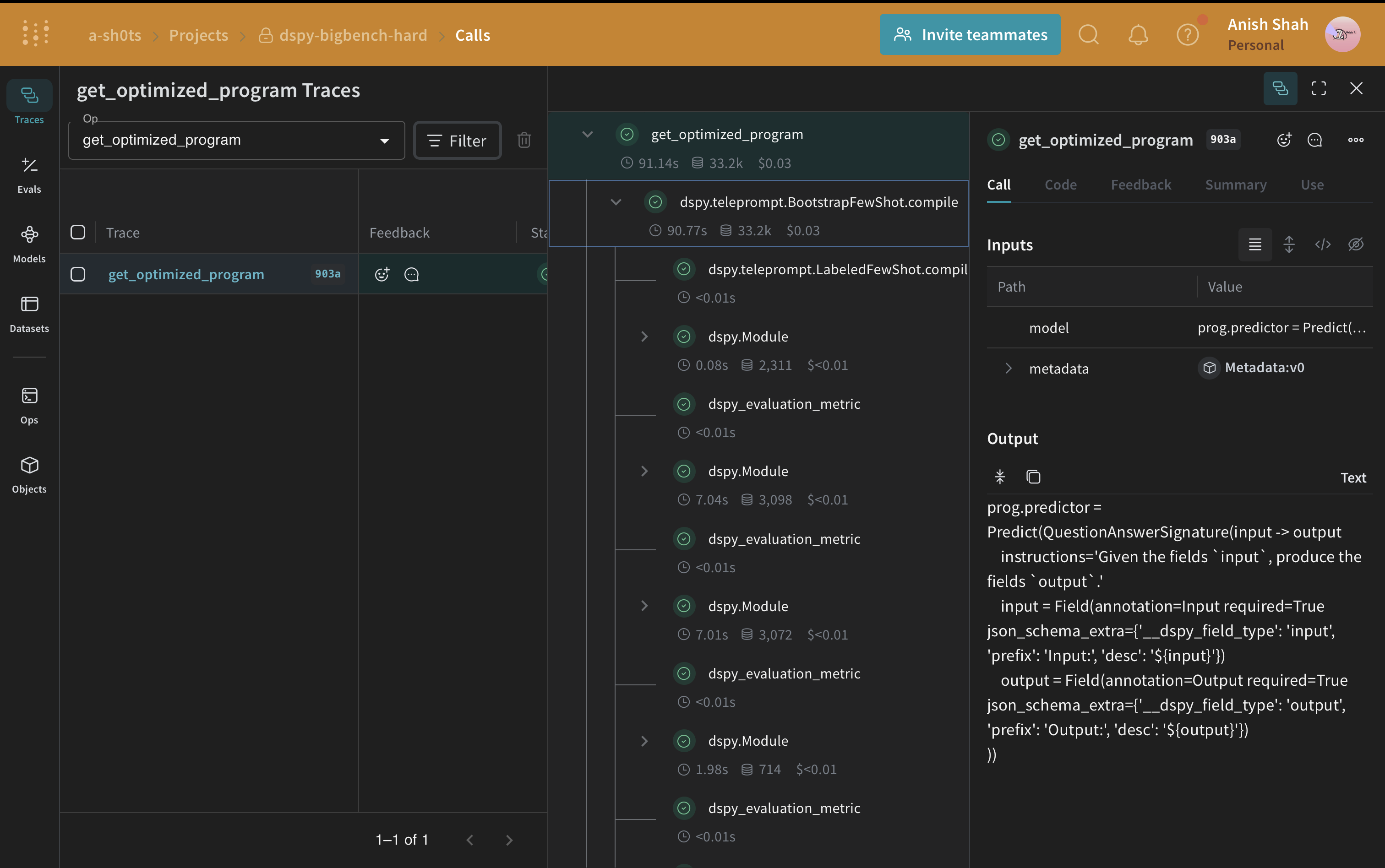 이제 최적화된 프로그램(최적화된 프롬프트 전략)이 있으니, 검증 세트에서 다시 한 번 평가하고 기본 DSPy 프로그램과 비교해 봅시다.
이제 최적화된 프로그램(최적화된 프롬프트 전략)이 있으니, 검증 세트에서 다시 한 번 평가하고 기본 DSPy 프로그램과 비교해 봅시다.
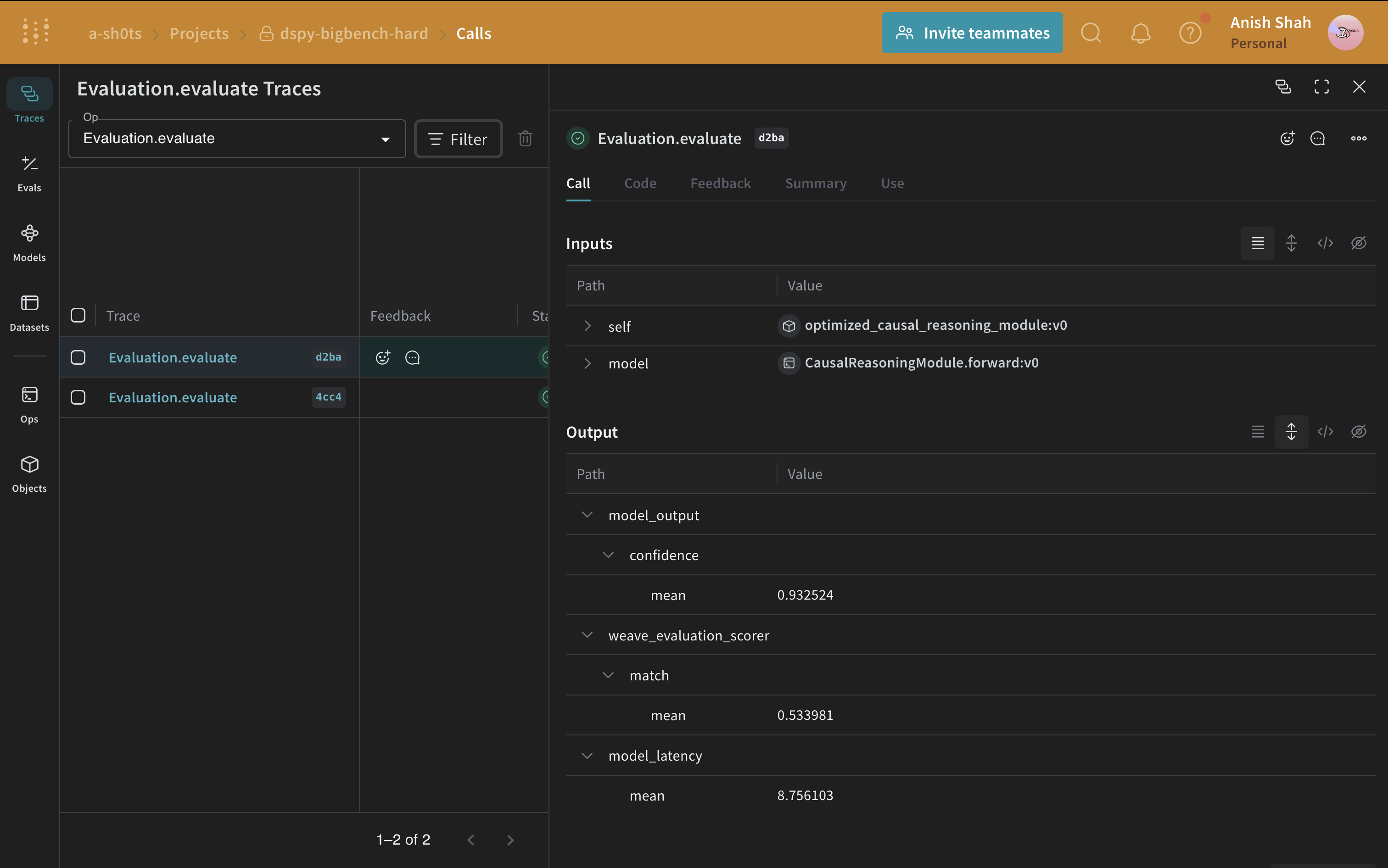 기본 프로그램과 최적화된 프로그램의 평가를 비교해보면, 최적화된 프로그램이 인과 추론 질문에 훨씬 더 정확하게 답변하는 것을 볼 수 있습니다.
기본 프로그램과 최적화된 프로그램의 평가를 비교해보면, 최적화된 프로그램이 인과 추론 질문에 훨씬 더 정확하게 답변하는 것을 볼 수 있습니다.